
Python转义符
- \ \ 反斜杠,在Python里面\是个符号,后面跟的是指令,两个\\只显示一个
- \’ 显示单引号
- \” 显示双引号
- \a 响铃(BEL)
- \b 相当于backspace,退格的意思
- \n 相当于回车符
- \t 相当于tab,换行一个tab占4个字符,前面字母如果是5个字符,tab位置就是3个以此类推(水平制表符)
- \v (垂直制表符)
- \r 相当于return(返回的意思),将光标移动到最开始的地方进行输出,以Pycharm里为准,IDLE里实现不了\r的功能
- \f 换页符
- \ooo 为八进制
- \xhh hh为16进制
载入模块
一共有3种方法加载模块 statistics模块为例 mean()计算平均数 median()中位数
- import statistics 这种方法就是每次引用前都要加模块名加函数
Data=[1,2,3,4] print(statistics.mean(data))这样的缺点是每次引用都要带模块名,优点就是不会造成与其他函数名冲突,一般在加载很多模块,然后容易冲突的情况下使用
- from statistics import mean,median (多个就用逗号隔开)
这样子的好处是这两个函数mean,median就可以不加模块名直接调用
print(mean(data)) 这样子一般在多次使用函数加不会冲突的情况下使用
- from statistics import * 这样子这个模块里所有的函数都不需要加模块名来调用,一般不推荐使用,比较容易和其他函数和变量冲突,例子和2一样
原始字符串
Raw strings(原始字符串)
1.在Python里面输入print(“D:\three\two\one”)的话会被python认为是转义符,可以通过\\来解决这个问题,在字符串面前+一个r也可以完美解决这个问题print(r”D:\three\two\one”)
长字符串
- 任意字母可以组成长字符串, abc=””” 内容””” 然后print(abc)就可以打印出来
- Print(‘123’ *3000)就可以打印3000遍123
赋值原则
- 以最后一次赋值为原则 在python中变量赋值是引用数据,而不是将数据放到变量里面,同个值则内存地址相同
- 赋值优先,从右到左,要是多项赋值的话.
- 右边赋值给左边
内置函数
input()接受用户输入的数据并且返回信息,默认输出字符串,如果是相加之类的运算需转换
int() 用于将指定的值转换成整数,如果读取到一个无法转换为整数的参数,则抛出 ValueError 的异常,浮点数转换舍弃小数点后的数
While: 循环语句,输入条件(结果得是布偶类型),达到条件要求就可以继续循环运行代码
Break语句,用来打破循环,得到结果为ture就打破循环(和continue类似),但是break是符合上面条件语句后不再循环,continue是按照要求继续循环,满足要求就执行与if平级下面的语句执行完后再循环,break只能跳出当层循环
level() 执行多条语句
Continue 当条件为ture的时候,就执行下面的语句,然后再回到循环体条件判断的位置
For 变量 in 可迭代对象://for循环依次从可迭代对象里抽取字符依次赋值给变量
Statement(s)
字符串,列表,元组,字典,集合都是可迭代对象
For 循环是将可迭代对象的内容依次取出,所以for循环也被称为”遍历循环”
字符串为迭代对象的话里面的数字或者字母就是单独拿出来进行循环,abc,拿a再拿b,列表就是整个abc,因为在列表里的时候abc就是一个独立的元素
- len() //获得对象长度并输出
- range() //一般来配合for循环 从括号里第一个数字开始,包括第一个数字(1,10,+2)从1开始,到10结束,不包括10,2是跨多少个位置, end=’!’循环后+个!
start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5)
- ord()将输入的数字转换成Unicode编码
- str() 将指定值转换为字符串
- list(元组) 将元组转换成列表
- float() 将指定值转换为浮点数
- chr()将指定10进制转换成ANSI对应的值
- sum()将整数类型int进行求和
- while 和for 循环都有适合的用法,while适合不知道要循环多少次但是有循环条件的时候使用 for就适合只知道次数的时候使用
- zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表,将两个列表中下标索引值对应元素组成分别的元组,一一对应,再用print(list(zip(list1,lsit2)))返回输出结果,list1或者list2多出来的元素就不会显示
- endswith(‘xxx’),判断字符串结尾是否为xxx,是就返回True,不是就返回False,startswith()就是判断开头
- eval()函数,将字符串转换为列表,元组,字典,””.john()函数则相反,去掉””
- map()函数,map(函数名,列表)列表内的对象都会执行函数,python2和python3差别比较大,python3不会直接显示值,只会显示对象在内存的地址,所以要加个list()去把他显示出来 #将函数作用到每个元素上并且组成新的列表
- filter(),用于过滤序列,过滤掉不符合条件的元素,并且返回fifilter对象,并且将转换为列表。filter(函数,列表),和map()差不多
- enumerate(list,start=0),#列出下标索引和元素以元组形式输出,配合for循环使用和range()差不多,针对于列表,默认是0,填了start后就是索引值从1开始
- 在python中,_ _xx_ _()的函数叫做魔法方法,指的是具有特殊功能的函数
#转换整数int(),浮点数会直接舍弃小数点,’36’ ‘36.1’前者可以转换,后者不可以转换成为整数。
#浮点数float()就可以将布偶和整数,字符串中的整数及浮点数转换成浮点数
#字符串转换,str(),这个可以将一切转换成字符串
#Ture=1 False=0
运算符
1.不满足就返回False
< 判断左边是否小于右边
<= 判断左边是否小于或者等于右边(两个符号满足一个就是返回True)
> 判断左边是否大于右边
>= 判断左边是否大于等于右边(两个符号满足一个就是返回True)
==判断左右两边是否相等
!=判断左右两边是否不相等
is 判断两个对象id是否相等(如果这两个值的数值类型相同,值也相同)
is not 判断两个对象id是否不相等
只要有0就返回0,没有就返回最后一个非0的数
判断语句
判断语句又称为分支语句,即判断条件成立执行,不成立执行另外一种情况,一般搭配运算符使用
1.基本语法:
if 判断条件(布偶值):
条件成立,执行语句
elif 判断条件:\\不成立就继续判断Elif,成立则不执行下面代码块
elif:
else:
上面条件均不成立执行
可以缩写print(a) if a >b print(b) 如果a大于b,就会执行print(a),如果小于就会执行print(b)
如果是 if 变量或者其他值: \\这时候就判断他的bool值,大于0就是ture,注意如果是input()将输入的转换成字符串再赋值给变量的话,那就是布偶值是Ture,0或者空是False
编程
- 缩进一样叫并列,并列的语句地位都是一样的,都会执行并列的语句,小一缩进的可能会被忽略,然后不被运行,代码块必须有同一缩进,条件成立就执行,不成立就不执行
- 注意数字和字符拼接 都要用str()
- 在判断语句中,如果不知道下一步要做什么,先用pass站位,以防报错
- ==对比的是value值,is比较的是id值
数字的概念
- 浮点数在python里面是小数的意思
浮点数由于在计算机底层是2进制运算,所以会不准确,这时候加载模块提升精准度
From decimal import Decimal Decimal()
- 整数在python就是整数
- 复数:我们把形如 z=a+bi(a、b均为实数)的数称为复数。其中,a 称为实部,b 称为虚部,i 称为虚数单位。当 z 的虚部 b=0 时,则 z 为实数;当 z 的虚部 b≠0 时,实部 a=0 时,常称 z 为纯虚数。复数域是实数域的代数闭包,即任何复系数多项式在复数域中总有根。
- e计数法表示的是10,1e6=1000000,e后面跟着是10的多少次方
- 素数又称质数。所谓素数是指除了 1 和它本身以外,不能被任何整数整除的数
- 8,16,2进制 0o177,0x9ff,0b101010
- Set(‘spam’),{1,2,3,4} 集合
Python支持的数字运算
()优先级最高,复合运算符中先算右边的表达式
- x+y \\x+y的结果
- x-y \\x-y的结果
- x * y \\x乘以y的结果
- x / y \\x除以y的结果
- x // y \\x除以y的结果(地板除)取目标结果小的最大的整数 x==(x // y) * y+(x%y)
- x % y \\x除以y的余数
- -x \\x的相反数
- +x \\x本身
- abs(x) \\x的绝对值
- int(x) \\将x转换成整数,字符串转换成int,字符串中不能有小数点,有就会报错,浮点数则会直接舍弃小数点后的数
- float(x) \\将x转换为浮点数
- complex(re,im) \\返回一个复数,re是实部,im是虚部
- c.conjugate() \\返回c的共轭复数
- Divmod(x,y) \\返回(x//y,x%y)求出x,y的地板除的值,和相除的余数\\
余数的符号应与除数符号相同 除数为正数,则余数也为正数,除数为负数则余数也为负数

布尔类型
- Ture和False(在运算里面true=1False=0 ),空列表和及字符串等都是False
- 定义为flase的对象(None)空和flase(假)
- 值为0的数字类型:0,0.0,0j,Decima(0),Fraction(0,1)
- 空的序列和集合:’’,(),{},set(),range(0)
逻辑运算符
- and 左边右边同时为true,结果为true 如果结果为true,一边为False就返回False,显示右边的,因为是最后一个确定真假的
- or 左边右边其中一个为true,结果为true,一边为Trun就都是Trun,如果左边的值为ture,就显示左边的值
- not 如果操作数为True,结果为False,如果操作数为Flase,结果为True(取相反结果)
- or and 两个逻辑运算符遵循的是短路逻辑,短路逻辑:短路逻辑的核心思想:从左往右,只有当第一个操作数的值无法确定逻辑运算的结果时,才对第二个操作数进行求值。遇真就停
- in 和no in 判断字符或者数字在不在字符串或者变量里,在就算是True,不在就是False
运算符优先级
注意:优先级数字越大优先级越大
| 优先级 | 运算符 | 描述 |
|---|---|---|
| 1 | lambda | lambda表达式 |
| 2 | if - else | 条件表达式 |
| 3 | or | 布尔”或” |
| 4 | and | 布尔”与” |
| 5 | not x | 布尔”非” |
| 6 | (in,not,in,is,is not,<,<=,>,>=,!=,==) | 成员测试,同一性测试,比较 |
| 7 | | | 按位或者 |
| 8 | ^ | 按位异或 |
| 9 | & | 按为与 |
| 10 | <<,>> | 移位 |
| 11 | +,- | +,- |
| 12 | *,@,/,//,% | 乘法,矩阵乘法,除法,地板除,取余数 |
| 13 | +x,-x,~x | 正号,负号,按位翻转 |
| 14 | ** | 指数 |
| 15 | await x | Await表达式 |
| 16 | x[index],x[index:index],x(arguments…),x.attribute | 下标,切片,函数调用,属性引用 |
| 17 | (expressions…),[expressions…],{key:vlaue…},{expressssions…} | 绑定或元组显示,列表显示,字典显示,集合显示 |
循环优先级
1.先进行完小循环再进行大循环
位置索引
- 正向1,2,3,4,5,6,7,8,9…
- 反向-5,-4,-3,-2,-1
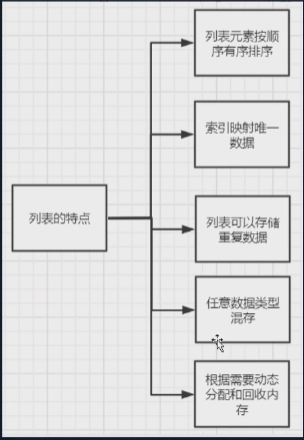
列表
[ ]表示列表,从0开始,0是1,1是2
和range()类似
创建列表 1.a = [] 2.a = list()
- 增 1.append()添加元素,只能添加在最右侧
- extend()批量添加元素,表名 1.entend(表名2),这样子就
- 表名[len(表名):]= [1,2,3] (末尾添加)
- 插入 表名.insert(0(索引位置),0) 就在列表第一位添加0
- 删 1.表名.remove(元素)如果列表存在相同的,就会删除第一个 2.表名.pop(索引位置)从0开始 3.表名.[1:3] = [] 删除索引1到3所有的内容
- 改 1.表名[位置] = 要改的元素只能改一个 2.表名[3:0] = [ ]改位置3以后的所有元素 3.通过找到索引值修改元素 s[s.index(元素)] = 新元素
- 查 1.s.count(x) 返回 x 元素在 s 列表中出现的次数 2.在不知道某个元素的索引值的时候通过表名.index(“元素”)找到索引值 索引值=位置 3.找到所有元素的位置的方法 s.index(要找的元素,开始的位置,结束的位置)
可以配合not in 或者in 来查询是否在列表里
8.del 表名[0],删除索引位置为0的元素

其他方法:
- s.count(x) 返回 x 元素在 s 列表中出现的次数
- s.copy() 返回 s 列表的一个浅拷贝,相当于 s[:], y =s.copy浅拷贝
- s.reverse() 原地反转列表中的元素(第一个与最后一个互换,第二个与倒数第二个互换,第三个与倒数第三个互换,…)
- s.sort(key=None, reverse=False) 对列表中的元素进行原地排序(key 参数指定一个用于比较的函数;reverse 参数用于指定排序结果是否反转)空就是从小到大。可以这直接实现大到小,false就是从小到大,True就是大到小
新表 = Sorted(要排序的表名),这样子也会对旧表进行排序,但是会产生新的表名 - s.index(x, start, end) 返回 x 元素位于 s 列表的索引值(start 和 end 可选,指定开始和结束位置,不过返回的索引值仍然是以序列开始位置计算的,属性和range()差不多);如果找不到,则返回 ValueError 异常,如果有重复的元素,则返回元素首次出现的索引位置
- s.reverse()列表每一个对应的倒序索引互换([1]位置的数据会去到[-2]#逆序没有排序效果),s.sort(reverse=true)
列表切片:
表名.[1:6:2],第一个是列表开始的地方,第二个是列表结束的位置,和range()类似,不包括结束位置,第三个是步数,默认是1
[::2]这样就是从头到尾,步长为2
Start位置不写默认就是从头开始 end位置不写默认就是从最后倒数
[::-1]从列表倒数,-2就是步数为2
- 清除列表中全部元素,表名.clear(),这种会剩个[],del 表名这样子删的最彻底
如果列表x=列表y,则x修改数据时,y也会随之改变如果没有嵌套列表就可以使用这个,有嵌套列表的话不建议使用改数据也会跟随改变y= copy.copy(x)也是浅拷贝
深拷贝需要加载模块import cpoy, y=copy.deepcopy(x),这样就是深拷贝
浅拷贝用的都是同一对象,深拷贝则创建新的对象
A = [i for i in range(1,10)] 依次赋值给i,i再作为列表元素,创建列表方法之一
S=[0,0,0]
For i in range(3)
S[i]= …
这样子是修改列表数据为目的,列表需要有元素
(Else:)else也可以搭配else和for使用,当循环完之后不满足Ture条件的时候就会执行else后的语句,满足条件跳出循环后就不会执行else下面的语句
元组
- 元组用(),也可以不用()直接= ,创建方法: 1. a = (‘a’,) 2. a= ‘a’, 3.a = tuple((‘a’,))
- 不支持修改,支持切片[0]
- 只生成一个元素的元组(520,)不加逗号就不是
- 想修改就嵌套列表,a[1].append(100),这样子添加
不可变序列:字符串,元组
可变序列:列表,字典 - 元组拆包,例 a = (“蔡徐坤”,2),name,age = a。Print(name),print(age),name显示的是蔡徐坤,字符串类型,age显示的是3,整数类型。多用于将函数返回值进行定义全局变量。
Name,age = cxk(),如果cxk()里返回的是(“蔡徐坤”,2),就可以这么使用 - 元组去重复数据可以使用set()函数转换成集合,也算一种修改,也可以转换成列表进行修改,两种办法修改完后再转换成元组,理解为变相修改
字典
- {}符号来表示字典
- dict(字典) = {key1. : value1, key2 : value2, key3 : value3 } key=键 vlaue=值 + :可以变成= dict={key=123456}
- 注意:dict 作为 Python 的关键字和内置函数,变量名不建议命名为 dict ,可以使用判断语句 in 和not in(key),key不可以重复value可以重复,字典不能使用[0]索引
- 键必须是唯一的,但值则不必,值可以取任何数据类型,但键必须是不可变的,元组可作为键
- A = {} A = dict()均可以创建字典
- print(“Length:”,len(A))打印字典中的数量
- 想看字典里对应的值,print(A[‘键’]),print(A.get((‘键’))
- 更新信息A[‘键’]=”要修改的值”
- 添加信息A[“键的名字”]=”值”
- 删除键 del A[“键的名字”]
- A.keys()返回所有键 A.values()返回所有值 A.items()返回所有键对值(for keys, vlaues in A.items())将返回键和值依次赋值给keys和values,items()将键值转换成元组返回

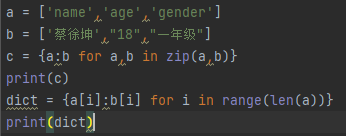
将连个列表拼接成字典,d = {表名1:表名2 for 表名1,表名2 in zip(表名1,表名2)}
- 字典的遍历以及处理,字典由键值组成,如果想通过提取键或者值达到某种效果但是又两者不可兼得的情况下,利用元组拆包。For data in dict1(),a,b =data #元组拆包,data获取到的值是元组,我们进行元组拆包就可以获得到字典中的键值对应的值

集合
不允许重复,重复会自动删除,集合没有顺序不适合存数据操作,不同于列表,支持in 和not in
- 创建方法 1.a = {1,2,3,4,5,6,7,8},2.a =set((range(6)),3.a =set((1,2,3))(set是创建集合的函数),如果这样子创建的的字符串会无序打印4.s = set()
- 增加元素,a.add(1)只能加单个元素,a.update({1,2,3,4,5})可以添加多个元素,可以为列表,元组等
- 删除元素a.remove(元素),没有该元素就会报错,a.discard(元素)存在就不会报错,不存在也不会报错
- a.pop()弹出,用的比较少
- issubset()查询集合A是否为集合B的子集,print(a.issubset(b)),判断是否
- issuperset()查询集合B是否为集合A的超集print(B.issuperset(A)),判断是否
- isdisjoint()查询集合B是否为与集合A有交集Bisdisjoint(A)这里比较奇怪,有交集会返回false,判断是否
- Intersection() print(a.intersection(b),a & b(和左边的效果一样))显示出a与b的交集,两个集合相同的数据
- Union() print(a.union(b),a | b)显示出a 与 b的并集 (显示出两个集合相加后的数据,重复的自动删掉)
- Difference() print((a)difference(b),a -b )显示出a-b后剩余的数据

字符串
字符串可以切片[0],是不可变类型,不具备增,删,改等操作,进行这些操作后产生新的对象,[::-1]倒序打印全部 hello>olleh。支持相加a+b=ab
- x赋值为字符串
- x.count(“要查找的字符”,0,5)下表索引区间,查找在字符串中出现了多少次,没有返回0
- x.find(“要查找的字符”)从左往右的下标索引 //找不到就会显示-1
- x.rfind(“要查找的字符”)从右往左 //找不到就会显示-1
- X.index(“要查找的字符”) //找不到会报错,和find差不多,但是会报错
- X.rindex(“查找要查找的字符”)倒序查找要查找的字符
- X.strip(),删除头尾空白字符和行,只能删除头尾,针对字符串
- X.upper()将字符串里的全转换为大写
- X.lower()将字符串里的全转换为小写
- X.swapcase()将字符串里面的大写转成小写,小写转成大写
- X.capitalize()将字符串一定字符转换为大写
- X.title()将字符串里的首位字母变成大写
- X.center(20,’*’)第一个是想要的长度,第二个是填充的符号使得居中对齐
- X.ljust(20)填充使得靠左对齐,不写什么符号就是默认空格
- X.zfill(20)填充使得靠右对齐,不写什么符号就是默认是0
- X.startswith(“子字符串”,1,20)检查字符串是否为子字符串开头,是就返回True,不是就返回False,支持索引位置。还有其他的判断字符串是不是全是字母或者数字,这里没写
- X.endswith(“子字符串”,1,20)检查字符串是否为子字符串结尾,是就返回True,不是就返回False,支持索引位置
- X.split(sep=’|’,maxsplit=1)分割字符串,分割出来就是独立的字符串,默认是空格,可以指定对象,sep是指定分割对象,maxsplit是指定分割次数,默认从左到右,则rsplit()和split相反,从右到左开始分割,用法一样,方向不一样(分割完后将结果转换为列表)
- X.replace(‘字符串中需要替换的字符串’,’要替换的字符串’,’个数’) 字符串替换操作,如果有多个需要替换的字符串需要写明次数,默认全部替换
- 列表转换成字符串,lst=[‘aa’,’bb’]类似这种转成完整的字符串,print(‘|’.john(lst)),这样子逗号都会被去掉使用|来连接成一个单独字符串,元组同样的方法也可以实现,不填符号就连在一起组成字符串#将[]去掉,里面内容拼接在一起不填””.john就是直接连接
- “#连接的字符”.john(#可以为列表,元组,集合),这个函数的作用是将列表,元组,集合(#集合没有顺序)转换成字符串,也可以直接print(“,”.john(list1)),针对于序列,不能直接写进参数

- 字符串比较操作:
运算符:>,>=,<,<=,==,!= 比较字母大小的话用ord()函数去查看,会返回数值大小,如果第一位就小,就直接返回运算符对应的结果,第一位比不出来就第二位,向下推
字符串判断操作:

公共操作
- 字符串:
字符串拼接,使用+号, str3 = str1 + str2
字符串复制,使用*号str2 = str1*2
‘a’ in ‘abcd’ True ‘a’ not in ‘abcd’ False #返回相对的bool值
- 列表:
列表合并,使用+号, list3 = list1 + list2
列表复制,使用*号 list2 = str1*2,会将两个列表合并成一个列表,就复制数据,不复制列表
‘a’ in [‘a’,’b’,’c’,’d’] True ‘a’ not in [‘a’,’b’,’c’,’d’ False #返回相对的bool值
- 元组:
元组合并,使用+号, t3 = t1 + t2
元组复制,使用*号, t2 = t1*2
a’ in (‘a’,’b’,’c’,’d’) True ‘a’ not in (‘a’,’b’,’c’,’d’) False #返回相对的bool值
- 集合
集合没有合并或者拼接
集合没有*号这个用法
a’ in {‘a’,’b’,’c’,’d’} True ‘a’ not in {‘a’,’b’,’c’,’d’} ) False #返回相对的bool值
- 字典
字典没有合并或者拼接
字典没有*号这个用法
字典比较麻烦,in 和not in 要分别对应值
查键和值

查键括号可加可不加

查值括号可加可不加

- 公共函数:
len()#计算长度
del() #彻底删除,正常会留下括号或者花括号
max() #计算对象最大值
min()#计算对象最小值
range() #将可迭代对象依次输出,配合for循环使用
enumerate() #列出下标索引和元素以元组形式输出
三目运算
三目运算符也叫三元运算符或者三元表达式
条件成立执行if语句,条件不成立执行else语句
A = 1 B = 2
Print(A if A < b else B) 条件成立返回A,条件不成立返回B,这里返回A
推导式
列表:#[表达式 for 变量 in 列表 if 条件] #元组和集合这方法大致相同,括号不一样
- 正常列表推导式:list1 = [i for in range(1,11)] 将1到10添加到list1空列表中
- 带if的列表推导式:list1 = [i for i in range(100) if i % 2 ==0 and i % 7 !=0] 将1~100中偶数和非7的倍数添加到列表中
字典:#{键:值 for 变量 in 可迭代对象 if判断}
字典生成:
- dict2 = {i:i**2 for i in range(1,11) if i %2 ==0} #将偶数返回作为变量生成字典,键为变量,值为变量的平方
 ,
,
两种方法,输入结果一致
转换
1.列表,集合,元组,字符串之间可以互相转换
优化字符串
这两种都是定位法去进行优化填充字符串,一般是用索引位置填充,括号内要注意要填充变量的位置,直接用变量名也可以
- format()函数在字符串中起到优化字符串的作用,例如多处地方要改,多处地方需要替换的情况下可以使用跟在字符串后面”””sfgaasfga”””.format() 有很多种方式,位置替换
abc = “””
{0}洗尘埃道未甞,甘于名利两相忘。
{1}怀六洞丹霞客,口诵三清紫府章。
{2}里采莲歌达旦,一轮明月桂飘香。
“””.format(“鸡”,”你”,”太”)或者跟变量,这种位置填补要注意列表位置
“鸡你太”分别对应的就是{0},{1},{2},{0},{1},{2}也可以变成字母或者单词,在format()里说明就好
- 占位符填充字符串,和上面一样,都要先赋值变量,让其自动填充,减少多余代码
%s = 字符串(全能选手,都能以字符串形式输出)
%d = 有符号十进制整数
%f = 浮点数
%u = 无符号十进制整数
%o = 八进制整数
%x = 十六进制(小写OX)
%e = 小数点后面6位有效数字,以指数形式输出实数
%g = 根据大小自动选着f或者e格式,切不输出无意义的0


使用格式化如上

结果

变量填充:print(f’我叫{name}’)这个name如果存在并且赋值过,那就会自动填充,f的作用就是这样
内置对象
- numbers 数字 1234,3.1415,3+4j,ob111,Decimal(),Fraction()
- string 字符串 ‘spam’,”Bob”s”,b’a\x01c’,u’sp\xc4m’
- lists 列表 [1,[2,’three’],4.5],list(range(10))
- dictionaries 字典 {‘food’: ‘spam’,’taste’:’yum’},dict(hours=10)
- tuples 元组 (1,’spam’,4,’U’),tuple(‘spam’),namedtuple
- files 文件 open(‘eggs.txt’),open(r’C:\ham.bin’,’wb’)
- set 集合 set(‘abc’,{‘a’,’b’,’c’}
- other core types 其他核心类型 Booleans,types,None 布尔,类型,无
- promgram unit types program单元类型 Functions,modules,classes 函数、模块、类
- implementation-related types 实施相关类型 Compiled code,stack,tracebacks
编译代码、堆栈、回溯
python程序中处理的每样东西都是一种对象
模块
- os os.system() (调用ftp模块)
- sys ()
- ftplibs (关于ftp)
- time模块(主要等上面代码执行完)
- socket (通信模块)
- image PIL (图片隐写)
自定义函数
定义:在编程中比较忌讳重复的代码,所以这时候就需要我们去定义函数然后就不会重复代码,定义在类外面的叫函数,定义在类里面的叫方法,retrun返回值后就不会执行函数下面的代码
- 变量:在def定义里,def代码块里面的算是局部变量,出了def这个自定义函数之后,python就不承认这个变量了。
- 如果不返回值,那么print(abc(a,b))的时候会显示None,retrun空格+要返回结果的变量
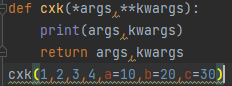
- Def cxk(a,b): 在定义函数的时候a和b是形参(形式参数),定义完cxk(3,6)3和6就是实参,定义函数的时候无法事先确定传递位置实参个数时使用:(可变参数def cxk(*abc),这时候*abc就代表多个参数,在cxk里面以元组方式存储,关键形参就是def cxk(**abc):,**abc的数据以元组方式存储,cxk(a=10))一个*就是元组,两个*就是字典,只能定义一个可变参数
- 数据透明,如果数据不透明,全局中就不能引用,就变成局部变量,所以在def代码块里面就可将局部变量转换成全局变量,使用global 变量名 进行转换,可以传回多个,但是cxk(a,b)里面的ab就不能传回来,因为是函数的参数,而且被定义了。global必须在def自定义函数的最前面,先声明再定义,不然会报错未定义变量
- 函数的返回值可以当做参数传递,demo2(demo1())
- retrun返回多样值的时候值将自动添加到元组里
- 元组拆包,例 a = (“蔡徐坤”,2),name,age = a。print(name),print(age),name显示的是蔡徐坤,字符串类型,age显示的是3,整数类型。多用于将函数返回值进行定义全局变量。
name,age = cxk(),如果cxk()里返回的是(“蔡徐坤”,2),就可以这么使用
- 将实参转换成元组和字典,def(*args,**kwargs):

- 自定义函数之后配合map()函数来实现将列表中,每个元素执行对应的函数,将列表中每个元素执行g2函数


- 默认参数,不往函数里传入参数的话就会自动使用默认参数,默认参数的定义:
def cxk1(name=”蔡徐坤”,age=16),不往里面传参的话就会使用默认参数,传参只需要
cxk1(”蔡徐坤”,18)
11.不定长参数,当不知道要传多少个参数进去的时候就用*args#将传入的数据转换成元组,**kwargs适合处理带值的,传入值的时候输入name=”蔡徐坤”,这样子传入数据,例如字典等。def cxk1(*args) :,然后会自动生成一个变量叫args,生成的*args为元组
函数的递归
- 函数的递归就是自己调用自己,=函数的内部自己调用自己
- 必须有出口 = 必须有停止条件
- 递归必须调用自己

匿名函数
- lambda(),短形匿名函数 #默认参数的lambda表达式
格式: cxk#(匿名函数名) = (lambda b,c,a#(形参):a+b+c#(要执行的操作))(2,4,6#(实参,要传进去的参数)) #不传参就空着要有两个括号
- #不定长参数的lambda表达式,不加括号会报错(args,kwargs),支持切片

- 嵌套使用map()调用

- 匿名函数排序

编码
x赋值为字符串,a为加密过的数据
- a = x.encode(encoding=’加密方式GBK,UTF-8等’)各种中文编码占字节也不一样
- 解码为print(a.decode(encoding=’编码格式’))解码,解不出来回报错
- gbk其实就是 ANSI,专门为中文设计,尽量使用UTF-8,因为是国际标准,文件头中输入
#encoding = GBK 就将变成GBK格式
一闭三器
- 闭包:全局变量可以随意修改,闭包的作用就是为了防止不能随便修改。嵌套定义函数,
1 | def fun1(): #调用fun1()的时候不会执行fun2() |
调用fun1()的时候把他赋值给a,a = fun1(),a()后就会自动执行fun2()
1 | def XS(abc): # 定义要执行的函数 |
- 装饰器:让代码看起来更优雅更简洁
1 | def fun1(): |
- 迭代器:获取对象迭代器,实现for range效果,魔术方法_ _inter_ _()和inter函数
1 | str1 = "python" #定义字符串 |
结果:
<str_iterator object at 0x000001ECE94FEFD0>
<str_iterator object at 0x000001ECE94FEBB0>
_ _next_ _魔术方法和next()函数效果一样,都是查看迭代器结果
 (几乎用不到)
(几乎用不到)
- 生成器:生成器的本质就是迭代器,生成器函数中有个关键字yield,yield与return的区别就在,yield和return的共同点就是都返回值。
yield:
1、是暂停函数
2、返回值后继续执行函数体内代码,
3、返回的是一个迭代器(yield本身是生成器-生成器是用来生成迭代器的);
精髓理解:返回后函数执行暂停,如果下面没有next和_ _next_ _就不会继续执行,会继续暂停
return:
1、是结束函数;
2、返回值后不再执行函数体内代码.
3、返回的是正常可迭代对象(list,set,dict等具有实际内存地址的存储对象)
精髓理解:返回后函数执行结束
异常处理结构
- 为了以防用户的使用中使得程序报错,就要用try: except 错误类型。来进行维护下面代码的完整运行,就算报错,except后也能运行下面的代码,捕获异常的顺序先小再大,为了避免可能出现的异常,一般最后放except BaseException(包含了所有错误 ) as e:,as 是把e缩写。Trackback模块也能实现这样的效果
try:
代码块
except Error类型:
报错后执行的操作
except except BaseException as e:
报错后执行的操作(except这个可以多个)
else: #如果try里面的程序运行完没有报错,就会执行这个
print(‘程序运行结束’)
finally: #无论程序报错还是没报错,都会执行这个语句
print(‘谢谢使用’)
异常类型大全
https://blog.csdn.net/qq_34238567/article/details/120737720
| 异常名称 | 描述 |
|---|---|
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| Exception | 常规错误的基类 |
| StopIteration | 迭代器没有更多的值 |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| SystemExit Python | 解释器请求退出 |
| StandardError | 所有的内建标准异常的基类 |
| ArithmeticError | 所有数值计算错误的基类 |
| FloatingPointError | 浮点计算错误 |
| OverflowError | 数值运算超出最大限制 |
| ZeroDivisionError | 除(或取模)零 (所有数据类型) |
| AssertionError | 断言语句失败 |
| AttributeError | 对象没有这个属性 |
| EOFError | 没有内建输入,到达EOF 标记 |
| EnvironmentError | 操作系统错误的基类 |
| IOError | 输入/输出操作失败 |
| OSError | 操作系统错误 |
| WindowsError | 系统调用失败 |
| ImportError | 导入模块/对象失败 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| LookupError | 无效数据查询的基类 |
| IndexError | 序列中没有没有此索引(index) |
| KeyError | 映射中没有这个键 |
| MemoryError | 内存溢出错误(对于Python 解释器不是致命的) |
| NameError | 未声明/初始化对象 (没有属性) |
| UnboundLocalError | 访问未初始化的本地变量 |
| ReferenceError | 弱引用(Weak reference)试图访问已经垃圾回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| NotImplementedError | 尚未实现的方法 |
| SyntaxError Python | 语法错误 |
| IndentationError | 缩进错误 |
| TabError Tab | 和空格混用 |
| SystemError | 一般的解释器系统错误 |
| ValueError | 传入无效的参数 |
| UnicodeError Unicode | 相关的错误 |
| UnicodeDecodeError Unicode | 解码时的错误 |
| UnicodeEncodeError Unicode | 编码时错误 |
| Warning | 警告的基类 |
| DeprecationWarning | 关于被弃用的特征的警告 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| OverflowWarning | 旧的关于自动提升为长整型(long)的警告 |
| PendingDeprecationWarning | 关于特性将会被废弃的警告 |
| RuntimeWarning | 可疑的运行时行为(runtime behavior)的警告 |
| SyntaxWarning | 可疑的语法的警告 |
| UserWarning | 用户代码生成的警告 |
| FileNotFoundError | 文件未找到错误 |
等…
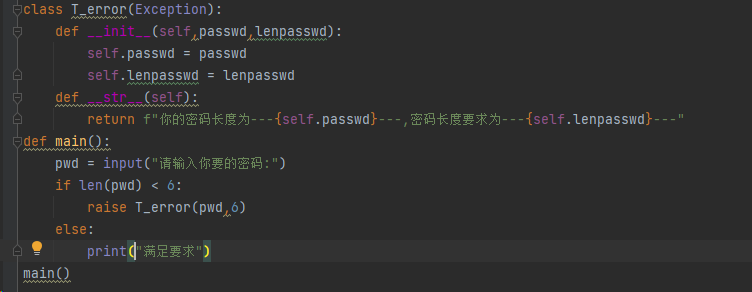
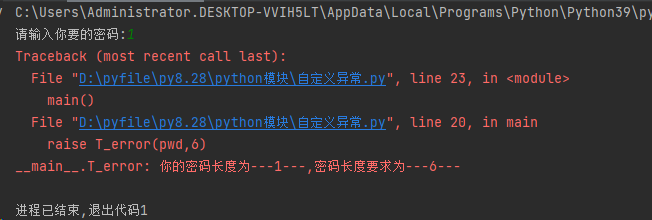
自定义异常
- 自定义异常类必须要继承Exception,并且包含init和str魔术方法(设置异常描述)
- 在python中,抛出自定义异常的语法为raise异常类对象
- 和创建类差不多,必须注意上面两项和定义_ _str_ _魔术方法
- 配合raise使用,raise关键字的作用是引发异常,通常在需要不满足情况下引发报错
面向过程与面向对象
面向过程就是一步一步完成,从头到尾,print(),int()那些函数都自己手敲,这叫面向过程,直接拿别人写好的代码,不管里面是什么,达到最终目的是的对象完成某些事情叫面向对象。
面向对象就是将编程当成一个事物,对外界来说,事物都是能够直接使用的,编程就是设置事物能做什么事情。面向对象有三大特征,封装,继承,多态。传入不同的对象产生不同的结果叫多态,子类继承父类叫继承,封装是定义私有属性,将方法和属性写入类叫封装。
类:
类与对象的关系,用类去创建一个对象,先有类再有对象,创建类的时候,类名采用驼峰命名法去命名,不要使用小写字母开头,My_Name,MyName,Myname
定义实例属性就是出厂自带,def _ _init_ _(self)下定义好,实例属性在创建类的时候就定义好了,只能通过调用类对象访问,类属性就是传入参数单独定义一个属性给类对象
beject默认是所有类的父项,内置函数dir()可以查看对象的属性,print(对象.dict)#输出对象有哪些属性以及参数,也可以查看类属性以及参数。Print(对象.class)查看对象由那个类创建,print(类.bases)查看类所有的父类。Object类中属性以及方法都可以修改,类括号里可以传值,也可以传对象

- 类与对象,真实存在的叫对象(实例),大概范围抽象的叫类
- Class cxk: #创建类对象(也叫类),与str,int的定义一样
- 类的最后要跟 def _init_(self,对象属性1,对象属性2等…):#这样子的目的是传递对象属性,上面的定义的def函数就是类方法,只有定义为类对象才能使用里面的函数。要是我们想在__init__返回输入值的时候先Global 数值1,数值2,再声明再定义,先声明数值1和数值2是全局变量,再赋值。会自动执行_ _init_ _(self)的代码,里面的print()等
- Def cang(self,aa) #类方法名字(self,参数1,参数2等):
- 定义为类对象的方法,ctrl = cxk(属性1,属性2)
- 调用类函数,定义完类对象后,ctrl.cang(要传给aa的参数) #这样子就可以直接调用,如果没定义为类函数,就调用不了类方法
第二种调用方法,类名字.方法(对象) cxk.cang(ctrl)
- 查看对象属性,print(对象名.方法),属性可以直接修改,class里面也可以,外面也可以(赋值)
- 静态方法,特点是不需要对象(实例)才能被调用,直接类名+名字直接调用。静态方法分为@staticmethod和@classmethod 下面的自定义函数中def gg(cls):,cls必须要。调用只需要class,名字1(),就可以
1 | class cxk: |
- 绑定动态属性,如果类里面没用定义我们想给某个对象单独加的属性,那我们就可以手动给对象添加动态属性,例:cxk(对象名).address(想加的属性名) = ‘dongguan’,只属于cxk的个对象,其他对象显示会报错,理解为开小灶

- 绑定动态方法,意思和定义和属性都和绑定动态属性一样,def定义在类外的叫函数,定义在类里面的叫方法,有时候我们想给对象单独定义一个方法,cxk(对象名).ctrl(动态方法名) = ctrl(已经定义的函数),将外面的函数定义为cxk的动态方法

- 面向对象的特征:
- 程序封装:python中没有专门修饰用于属性的私有,如果该属性不希望被在类对象外部被访问,在前边使用两个 ’_’,来进行封装,外部想查看的时候只可以print(对象名._类名__属性名)。才可以查看
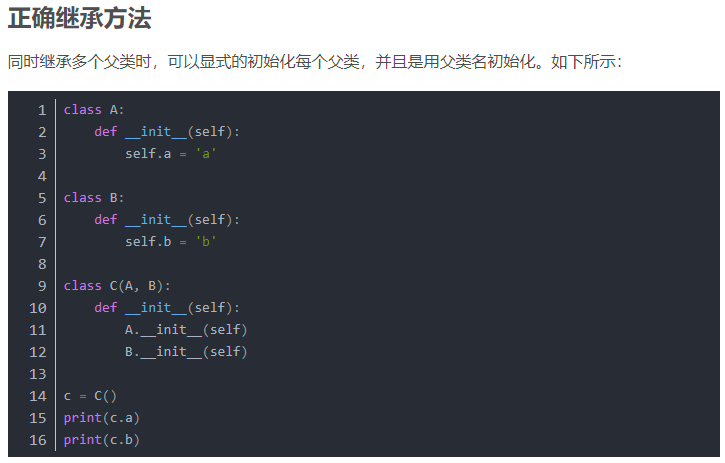
- python的类继承,子类可以直接调用父类的属性已经方法,创建类的时候,默认继承类是object,不填也是默认是object,class cxk(object),如果想创建他的子类:class ctrl(cxk):,就可以,子类可以调用父类的方法以及属性,使用super()函数调用父类cxk的属性以及函数:
1 | def __init__(self,name(父),age(父),address(子)): |
要是父类没有定义我们子类想添加的属性,只需要在使用完super()函数后,输入self.添加的变量名 = __init__括号里的属性值,右赋值到左,子类可以直接调用父类的方法,父类不能调用子类方法,一个子类可以指向多个父类,继承两个父类的时候尽量就别用global声明全局
变量,而且继承多个父类的时候不要用super(),尽量使用 父类名._ _init_ _(self,name,age)去调用父类方法,如果子类继承了父类的私有方法或者属性调用的时候得加类名。不能跨代继承,不能同时继承父类和爷类
- 方法重写,有时候父类的某种方法不适用于子类,我们就在子类中重写父类的方法,直接定义与父类相关方法的名字,再以这个名字定义方法,也算重写。还有一种是通过,
super().xxx#需要重写的父类方法名(),下面再跟上代码块

有时候会遇到重写完父类的方法和属性的时候,想调用回去就得重新定义一个函数,第一行是调用父类本来的属性,第二个是调用父类原本的方法

- 重写object类,可以重写object类里面的方法,_str_ return返回

- 特殊方法:

魔术方法:.
(1). 重新定义返回值,如果不定义_ _str_ _(self):。返回值就是内存地址,这里有return参数,相当于就是print()后返回的值,return跟上想返回的值
(2). _ _del _ _(self):,当对象销毁的时候用,当对象不再使用的时候_ _del _ _()方法运行,定以后自动执行里面代码,和_ _init_ _()里面会自动执行代码一样多层继承:当父类继承了两个父类(爷类)的时候,如果这时候需要调用爷类的方法,就需要在父类那重新定义一个方法,作用是调用爷类的属性以及方法,注意调用顺序,不然爷类的值会被覆盖,调用一次就会被覆盖一次,根据实际情况定义属性

- 多态:好处,有了多态,更容易写出通用的代码,灵活使用,实现步骤:1.定义父类,提供公共方法,定义子类,重写父类方法,传递子类给调用者,可以看到不同子类执行效果不同


深拷贝和浅拷贝
- 浅拷贝引用原来的属性,属性都是原来的,只有整体对象ID值不一样,其他都一样,修改被copy对象列表中的列表时,浅拷贝copy过去的列表中的列表的值也会变
- 深拷贝复制原来的属性,整体对象和个体ID值全部都变了,是一个独立的值,独立的地址,怎么修改都不会变任何东西
from copy import deepcopy
- 加载模块copy才能实现
with语句
- 当使用open()函数打开文件的时候,必然会使用到数据管道资源,如果运行完后不关闭会占用大量内存资源,而with语句就会帮我们自动关闭,做所有善后工作
Python模块
由函数,类,类方法,以及函数组成的叫模块,模块之间相互引用,相互调用
自定义模块
- 一个python文件就是一个模块,需要文件在源目录下才可以引用,需要在pycharm里面将文件夹设置成
 ,才可以引用,模块名就是python文件的名字,引用的方法和加载模块的方法一模一样。
,才可以引用,模块名就是python文件的名字,引用的方法和加载模块的方法一模一样。 - 被引用过的Python文件里面定义的方法,类,以及函数都可以被调用。
- if _ _name _ _ = ‘_ _main_ _’: #这句的语句的作用是以上的代码都是可以被其他python文件调用,只有在这个语句下的代码就只能在本文件下运行。
- 每一个python文件只有在本地的时候_ _name_ _才是_ _main_ _,被调用之后一定会被改成模块名
- 里面的变量也可以被引用
- From python文件 import *的时候,如果python文件里有__all__这个变量的时候,里面提及的函数名才能被调用,_ _all_ _ = [“函数1”,“函数2”]
Python软件包
- 当python文件过多,我们可以在pycharm中创建一个软件包,里面就存放python文件(模块),这样子的好处是避免命名和变量名冲突
- 如果想加载python软件包里面的模块 例:软件包名字为cxk,想调的包叫cang,函数叫ctrl
(1). Import cxk.cang 这样子就加载了python文件里的函数,使用的时候就要cxk.cang.ctrl(),这样子去使用这个方法,这样子比较繁琐,可以简化名字,在加载模块的时候,Import cxk.cang as gg1,这样Import cxk.cang就被赋值成gg1,再调用ctrl的时候只需要输入gg1.ctrl()
(2). from cxk.cang import ctrl #只导入ctrl(),ctrl被调用就不需要加软件包和python文件名
(3). from cxk.cang import * ctrl()被调用就不需要加软件包和python文件名
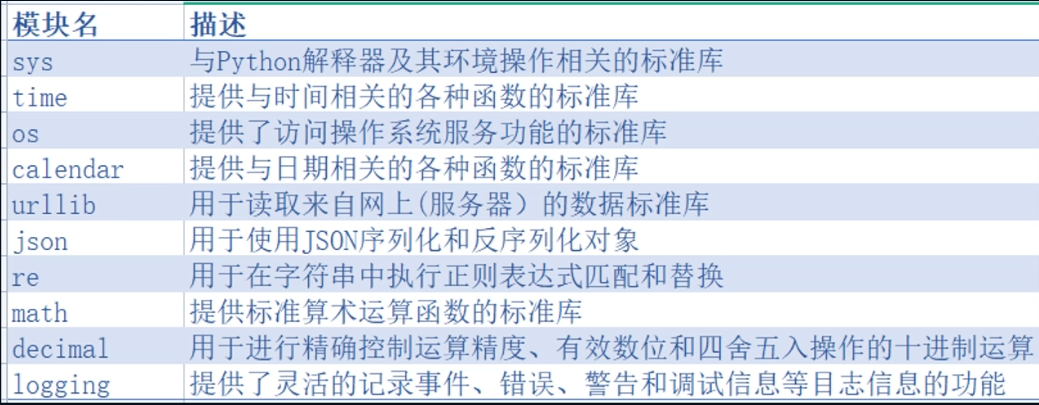
常用模块
时间戳
- time.time()就可以生成时间戳
- time.strftime()格式化时间
文件读写

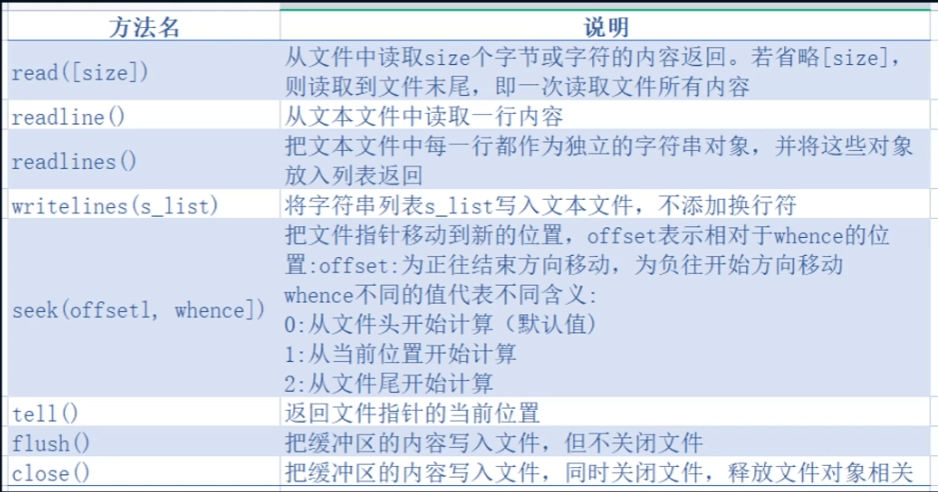
Read()用于读取整一个文件,以字符串形式输出
Readline()只读取文件的第一行,以字符串形式输出
Readlines()读取文件全部类容,以列表形式输出
OS


- os.system(“”)理解为在cmd和运行里输入命令
- os.startfile(‘路径’)
- print(os.getcwd)返回当前python文件所在位置
- print(os.listdir(‘路径’)) 显示当前目录下所有文件
- os.mkdir(‘文件夹名’)
- os.makedirs(‘A/B/C’)创建套娃文件夹
- os.rmdir(‘文件夹名’ )删除文件夹
- os.removedirs(‘’)删除多级文件夹
- os.path.abspath(‘路径’)获取文件或者目录的绝对路径 #import os.path
- os.path.exists(‘文件名’)寻找该目录下是否有这个文件,有就返回True,没有就返回False。