
爬虫的概念
模拟服务器与浏览器之间的通信,从而达到获取数据。分为三种爬虫,普通爬虫(获取整个网页的数据),局部爬虫(聚焦爬虫)只获取某一部分的数据,増量爬虫(只获取新的数据,旧的数据不获取).获取数据->解析数据->保存数据
网页
- session是登陆过后放到cookie里面,下次登陆就不需要重新登陆
- Cookie是存放用户数据的文件
- User-Agent:产生浏览器类型
- referer:防盗链,告诉服务器是从那个url跳转过来的
爬虫header
1.UA请求头,不写这个会被服务器识别到
2.设置代理,格式是”HTTPS”:”1.1.1.1” 协议是大写
requests
- requests.get()发起get请求. 括号后面可以加.text
- .text获取相应体的返回文本,字符串类型,有乱码则是有中文,Unicode型的数据
- .content返回的是bytes类型的数据=二进制的数据
- 解决乱码
data = requests.get(“http://xxx.com”)
data.encoding = “UTF-8”
print(data.test)
将编码编译成UTF-8,解决乱码,先编码再打印,字符串不能编码否则报错
allow_redirects=False禁止网页重定向
verify=False 忽略证书
import warnings
warnings.filterwarnings(‘ignore’) #忽略所有警告
url = “http://github.com“
- requests.post(url,headers=headers,data=data(浏览器表单))
- session=requests.session()创建一个session对象,目的就是为了携带登录过后的cookie
- data = session.post(url=url,hearders=headers) #获取数据
- from configparser import ConfigParser这个方法可以读取文件中的内容以至于来保护账户名和密码.
json
import json
- json.loads() #将json字符串转化为python类型(字典)
- json.dumps() #将python类型(字典)转化为json字符串
- json.dumps(dict,ensure_ascii=False) 这里ensure_ascii=False的作用是不以unicode编码显示文本
urlib
1.from urllib.parse import urlencode
urlencode()将字典对象转化成url参数
os
1os.path.splitext(url)[-1]提取 url中的文件名后缀
正则
- (.*?)想要的就括起来,不想要的就.*?可以不匹配
- re.sub字符串替换
# re.sub(r”匹配的内容”,”替换的内容”,字符串,count=1) count是替换的次数
re31 = re.sub(“蔡徐坤”,”ikun”,old_data2,count=1)
MongoDB
- show dbs 查看所有数据库
- use test (databasesname) 有这个数据库的话就会使用,没有的话就会自动创建
- db 查看我们在那个数据库里
- db.dropDatabase() 进入数据库之后(前提条件),删除数据库(作用)
- 刚创建的数据库 data_name并不在数据库的列表中, 要显示它,我们需要向 data_name 数据库插入一些数据。
- 在MongoDB里数据表叫集合
- show collections 查看集合(数据表)
- db.table_name(表名集合名).insert({name:”张三”}) 插入数据,可以多个,用逗号隔开
- db.table_name(表名集合名).find() 查看表中所有内容
- db.table_name(表名集合名).find({name:”张三”}) 查看关于张三的数据表中的数据内容
- db.table_name(表名集合名).update({name:”张三”},{$set:{name:”李四”}}) 将name=张三的name改为李四
- db.table_name(表名集合名).remove({name:”赵七”}) 删除name为赵七的数据行
- db.table_name(表名集合名).drop() 删除数据表
- 默认数据库端口为port = 27017,host = “localhost”
字体加密
- 字体加密在源代码像乱码一样的就是字体加密
- 字体文件在F12>网络>字体>woff结尾或者ttf结尾的,位置:1.
 3.点进去之后,找到一个链接,是一个css样式的url点进去之后搜索woff或者ttf找到字体文件
3.点进去之后,找到一个链接,是一个css样式的url点进去之后搜索woff或者ttf找到字体文件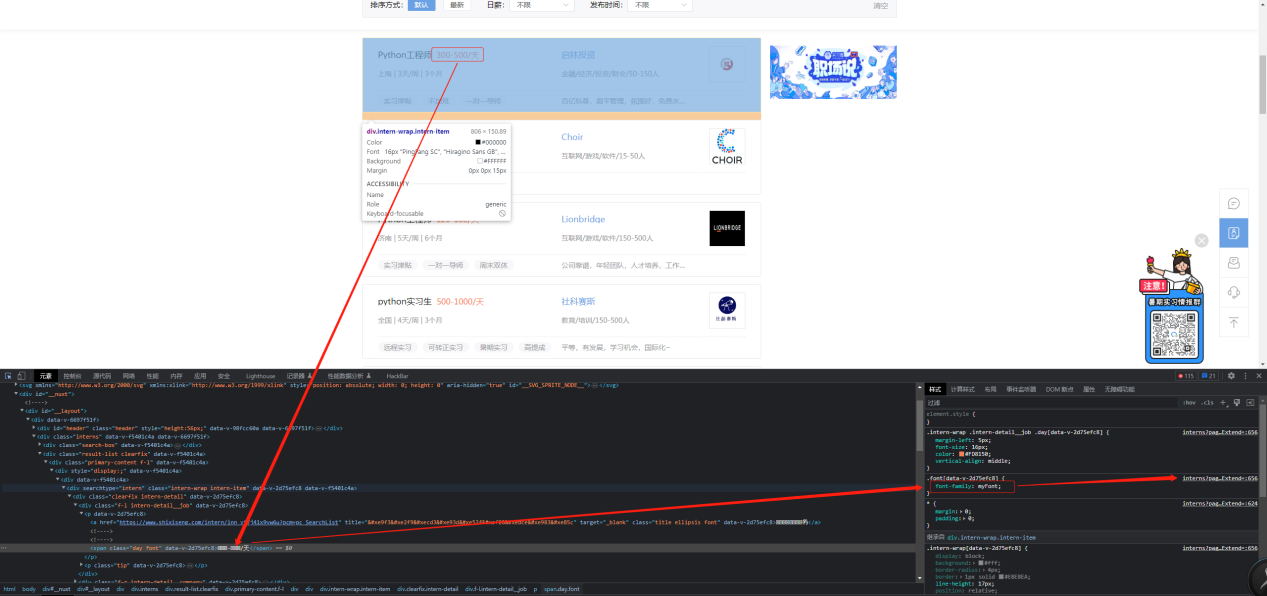 4.定位加密过的字体的html位置查看如上文所示的font-family,复制里面的url后加上域名访问就可以下载字体文件
4.定位加密过的字体的html位置查看如上文所示的font-family,复制里面的url后加上域名访问就可以下载字体文件
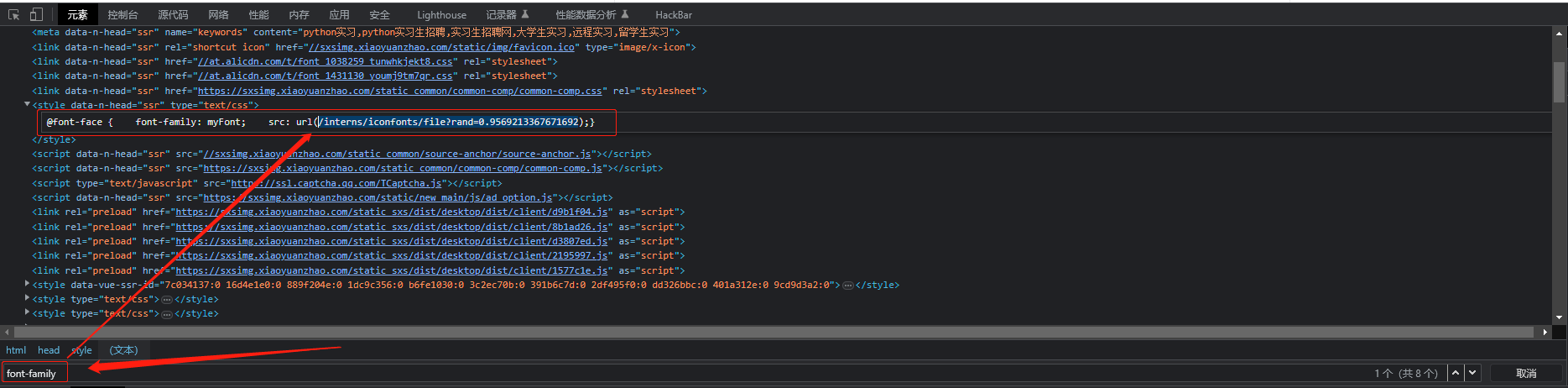
- 源代码里找font-family 找到后缀之后加到url后面
scrapy
- 先创建Scrapy项目,再创建爬虫,再调整配置文件
- 创建Scrapy项目: scrapy startproject name(项目名称)
- cd name(项目名称) — Scrapy genspider spider_name(爬虫名称) url(要爬取的网站)
- scrapy crawl spider_name(爬虫名称) #在爬虫目录下执行
- settings.py里设置LOG_LEVEL(报错等级),USER_AGENT(UA),ROBOTSTXT_OBEY(爬虫协议)
- LOG_LEVEL=ERROR 不报错的话不显示日志=没有杂七杂八的信息
- USER_AGENT=浏览器UA
- ROBOTSTXT_OBEY = False 不遵循爬虫协议
- DOWNLOAD_DELAY = 0.5 等0.5秒再获取数据,作用就是防止获取过快导致404
- ITEM_PIPELINES管道通道,里面的数据对应pipelines.py里的class,数字是优先级,数字越小优先级越高
- scrapy.Request(url=url,callback=(类中函数),dont_filter=False) #dont_filter=False默认去重复的url,callback将返回的数据返回类中某个函数
- 请求使用不同UA防止被限制做法,详细可看spiderdemo1中的配置
middlewares.py中(项目名)DownloaderMiddleware类中定义一个类属性,self.user_agent_list类属性列表里放UA值,然后在下面process_request中写入 def process_request(self, request, spider):
request.headers[“User-Agent”] = random.choice(self.user_agent_list)
“””random.choice(self.user_agent_list)的作用是列表中随机获取一个数值”””
- 设置代理IP池访问,首先需要先定义IP代理池
def process_request(self, request, spider):
request.headers[“User-Agent”] = random.choice(self.user_agent_list)
request.meta[“proxy”] = “http://“ + random.choice(self.http_IP)
“””设置代理IP”””
“””random.choice(self.user_agent_list)的作用是列表中随机获取一个数值”
def process_exception(self, request, exception, spider):
# “””如果请求失败了就返回到这个函数,异常处理函数”””
# “””切割request.url[字符串].split(“:”)[0] 通过:进行分割成列表,列表索引第一个就是http或者https”””
if request.url.split(“:”)[0] == “http”:
request.meta[“proxy”] = “http://“ + random.choice(self.http_IP)
if request.url.split(“:”)[0] == “https”:
request.meta[“proxy”] = “https://“ + random.choice(self.https_IP)
- settings.py中DOWNLOADER_MIDDLEWARES控制下载中间件的开关,不注释掉就算开启下载中间件
- POST请求去看实例例子分为:COOKIES_ENABLED,DEFAULT_REQUEST_HEADERS
reides
from scrapy_redis.spiders import RedisSpider导入类
- spider.py里类继承将scrapy.Spider换成RedisSpider
- 注释掉start_urls
- 在类属性中输入redis_key = “键(随便填没要求)”
- 在E:\Redis-x64-5.0.14.1安装目录中打开cmd输入redis-server.exe redis.windows.conf
- 在settings中添加
# 1.启用调度将请求存储进redis
SCHEDULER = “scrapy_redis.scheduler.Scheduler”
# 2.确保所有spider通过redis共享相同的重复过滤。
DUPEFILTER_CLASS = “scrapy_redis.dupefilter.RFPDupeFilter”
# 可选 不清理redis队列,允许暂停/恢复抓取。 允许暂定,redis数据不丢失
SCHEDULER_PERSIST = True
# 3.指定连接到Redis时要使用的主机和端口。
REDIS_HOST = ‘127.0.0.1’
REDIS_PORT = 6379
- 启动redis的shell,E:\Redis-x64-5.0.14.1中的redis-cli.exe,LPUSH Key values,key就是上面写的redis_key,value就是网址
- 将settings.py里的LOG_LEVEL 注释掉
- 然后开几个窗口进入当前spider(爬虫)的目录,同时启动就会自动链接到redis数据库,scrapy crawl spider
- 先启动完全部爬虫然后redis-cli.exe shell中下url地址命令运行爬虫
- 如果旧demo爬取过爬取过的网址需要重新进入RedisDesktopManager数据库清理数据
selenium
1 | option.add_argument('--ignore-certificate-errors') \# 忽略证书告警 |